
HackRF Pro Q+A
This post is a collection of some of the first questions asked by the community about HackRF Pro shortly after we announced it. Questions were asked by folks across our various social media accounts and in our Discord server. The answers given here are expanded versions of how the folks on our team responded to the public question we observed.
Why is it called HackRF Pro and not HackRF Two?
We felt that “Pro” expressed the idea that this is a refinement of the HackRF One design and that “Two” would more likely be interpreted as a revolutionary design. Our goal was to make a better HackRF One, not to make something as revolutionary as HackRF One was when it was new. We did consider “10”, “360”, and “Tau”.
What is the baseband bandwidth of HackRF Pro?
In normal operation, HackRF Pro supports up to 20 Msps with 8-bit I and Q samples over USB, just like HackRF One. Internally, HackRF Pro uses a sample rate of up to 40 Msps with decimation and interpolation performed in an FPGA. At lower USB sample rates HackRF Pro supports an extended-precision mode with 16-bit samples and an effective number of bits (ENOB) of 9 to 11, depending on the sample rate. We’re also developing a half-precision mode that uses 4-bit samples at up to 40 Msps over USB.
Some tools allow tuning up to 7.25 GHz with HackRF One. Is the limit of 7.1 GHz on HackRF Pro correct or just “suggested”?
7.1 GHz is the highest tuning frequency that should work reliably with HackRF Pro. You can try tuning up to 7.25 GHz, but it may fail (as may HackRF One). Unlike HackRF One, the performance of HackRF Pro up to 7 GHz is pretty good. HackRF One is quite lossy above 6.1 or 6.2 GHz.
Will there be different host tools and libraries for interacting with HackRF One vs. HackRF Pro?
We’re adding features to libhackrf and hackrf-tools. In the future, there may be some software specially written for HackRF Pro, but we anticipate that most software will continue to support any HackRF (including Pro, One, Jawbreaker, and rad1o). Backward compatibility was our primary goal for HackRF Pro. We tried hard to find ways to enhance the HackRF One design without radical changes to the architecture that would make compatibility difficult.
Will the hardware design be published online before this starts shipping?
Yes, like all of our electronic designs, we will publish the entire hardware design under an open source license online before shipping HackRF Pro. Our mission at Great Scott Gadgets is to put open source tools into the hands of innovative people.
Does that mean no more cracking the case open to set up triggers?
That’s right! Both CLKIN and CLKOUT can be configured to connect internally to either the trigger input or trigger output signal.
Is HackRF Pro compatible with Portapack H4M ?
Yes, we’ve tested with H4M and a few other PortaPacks, including the original PortaPack H1 from ShareBrained Technology. To the best of our knowledge, HackRF Pro is compatible with all PortaPacks; however, we can’t guarantee this.
Will Opera Cake be improved so that it can take full advantage of HackRF Pro’s frequency range?
A new revision of Opera Cake is likely, but we are not working on it yet.
How is RF port protection enhanced on HackRF Pro?
HackRF Pro has the same reverse current protection diode on the RF port bias tee that is present on newer revisions of HackRF One. This has been quite effective in improving amplifier robustness in HackRF One r9 and r10. In addition to over-voltage protection provided by the diode, the bias tee on HackRF Pro features over-current protection. HackRF Pro has new amplifiers, replacing the obsolete part on HackRF One. ESD protection has been enhanced on HackRF Pro, and the RF port is also protected from high RF power by a PIN-Schottky limiter.
Will HackRF Pro be suitable for classroom use?
Yes. We even added a little feature with classroom use in mind: It is possible to hardware-disable transmit mode by cutting one trace on the PCB.
Do you have any projects in mind for the extended frequency range of HackRF Pro?
We’re excited to try HackRF Pro with new very low power (VLP) devices that operate in the 6 GHz band. We’ve already had success receiving WWVB at 60 kHz.
Meet HackRF Pro
We’re thrilled to announce HackRF Pro, the newest addition to the Great Scott Gadgets family of Software Defined Radio (SDR) platforms!
Building on the legacy of HackRF One, HackRF Pro is an SDR peripheral that enables transmission or reception of radio signals from 100 kHz to 6 GHz. Like its predecessor, HackRF Pro is open source hardware and designed for versatility, whether you’re developing wireless tech, researching the security of wireless devices, tinkering as a hobbyist, learning or teaching about the RF spectrum, or building advanced custom firmware.

What Makes HackRF Pro Different?
HackRF Pro takes everything users love about HackRF One and improves upon it with many new enhancements. Here’s what you can expect:
-
Wider frequency range (100 kHz – 6 GHz operating; tunable from 0 Hz to 7.1 GHz)
-
Improved RF performance with flatter frequency response
-
USB Type-C connector
-
Built-in TCXO for superior timing stability
-
Upgraded logic from CPLD to a power-efficient FPGA
-
DC spike eliminated
-
Extended precision mode with 16-bit samples for low sample rates (ENOB 9–11 typical)
-
Half-precision mode with 4-bit samples at up to 40 Msps
-
More RAM and flash memory for custom firmware
-
Installed shielding for better RF isolation
-
Trigger input/output via clock connectors
-
Future-proofed PCB design with space for add-ons
-
Improved power management
-
Enhanced RF port protection
-
Facility to hardware-disable transmit mode
And yes, it’s still:
-
Compatible with GNU Radio, SDR#, and many other tools
-
Fully open source
-
Designed to work seamlessly with accessories like Opera Cake and most PortaPacks and third-party enclosures
Backward Compatible and Forward Thinking
HackRF Pro maintains backward compatibility with HackRF One—your existing software stack will work right out of the box. But we’re not stopping there. We’ll also be releasing a migration guide for developers who want to unlock HackRF Pro’s enhanced capabilities.
Preorder Now — Shipping This September
The HackRF Pro is now available for pre-order through our authorized resellers. Production begins in July 2025, with initial shipments slated for September 2025.
Please note: HackRF Pro comes in a sleek injection-molded plastic enclosure. USB cable and antenna are not included, but we recommend ANT500 as a great starter antenna.
Learn More
Visit the HackRF Pro product page for full specs and reseller pre-order links. The open source design, migration guide, and user documentation will be published prior to the first shipment. We invite you to join the discussion in the #hackrf channel on our Discord server!
HackRF One Availability Update
In December of 2022, we published a post about the HackRF One shortage and the hardware revision our engineering team completed so that we could continue manufacturing HackRF One. This hardware revision was necessary because we had difficulty sourcing critical components during the global chip shortage, mainly MAX2837- the RF transceiver IC used in every revision of HackRF One before r9. At the time of that post, we had a significant backlog of orders, and we were uncertain about how long production would take with COVID-19 slowing down operations at the factory in China. Today, we have good news: production of r9 went very smoothly, and the finished HackRF Ones started shipping to our warehouses in late February. As of now, all of the backorders for HackRF One have shipped to our resellers.
With over half of this last production sold and shipped due to the backlog, we are already preparing for a second 2023 production run in quick succession. Some lessons we learned from this HackRF One shortage are to invest in components early for products we know we want to keep producing and that components on the shelf are preferable to components on order if we can find them in stock at a reasonable cost. Fortunately, we found more MAX2839s (the substitute component for MAX2837 in r9) with good date codes and purchased them for a second production of HackRF One r9. We have also already purchased production quantities of several other HackRF One components that have very long lead times, like the clock generator chip, the CPLD chip, and the microcontroller. These components are on the shelf and ready for us to use in the upcoming production, so we don’t have any immediate concerns about unreliable chip distributor lead times impacting our production schedule. Most likely, it won’t be as easy to find more MAX2939s for future productions because that part is obsolete. That means there will only be one more production of r9, and subsequent hardware revisions will use MAX2837.
We are already ordering components with long lead times for HackRF One productions as far out as 2024. Before the chip shortage, it was entirely realistic to acquire all the components needed for HackRF One and complete a production run within six months. That is no longer practical because even though purchasing conditions are improving for some components, chip destributors are still quoting lead times of up to a year for several key HackRF One components. MAX2837 availability in particular remains scarce; the average lead time has tripled and the manufacturer price has nearly doubled. The MAX2837s we ordered in 2021 for Fall 2022 production have yet to arrive, although we do expect them to be delivered finally this summer. We plan to use those in a third 2023 production near the end of this year. We don’t know when (or if) things will return to normal with the chip market. So to prevent future production bottlenecks caused by one or two missing essential components, we will continue to plan manufacturing schedules and component orders further ahead of time.
We appreciate our resellers for their cooperation while we navigated the challenges presented by the global chip shortage, and their customers who waited patiently (some for months) for their HackRF One orders to be delivered. Thank you for being so supportive! We can’t understate this: you are the reason we are still here!
HackRF One Shortage
The past couple of years have been challenging for Great Scott Gadgets. The global chip shortage in particular has put demands on our team unlike anything we’ve faced in the past, and we have been working hard to navigate its effects on our supply chain for HackRF One and our other products. Revenue from the sale of hardware sustains our business, allows us to improve our existing products, and helps us to continue the research and development work that brings new and innovative open source tools to the community. If you have tried to purchase a HackRF One recently, you may have found that many of our resellers are sold out. That is because our resellers have orders in with us that we haven’t been able to manufacture and deliver (yet).
Despite careful planning and ordering components more than a year in advance, we are off-schedule with production of HackRF One. This is primarily due to the unavailability of two components that don’t have simple substitutions: HackRF’s clock generator chip (SI5351C) and RF transceiver IC (MAX2837). We made deposits to chip suppliers for these two components in Autumn of 2021, and had planned to complete production in Autumn of 2022. Based on the lead times given to us when we placed our orders, this should have been a realistic timeline. However, in the second quarter of 2022, we learned from our contract manufacturer that MAX2837 would be delayed to June of 2023, almost a year later than promised. SI5351C was delayed to March 2023. We even had a backup order of SI5351C that was canceled by the supplier completely.
These component delays could have delayed the production planned for Autumn of 2022 to late Summer 2023 and caused a lengthy HackRF One shortage. Thankfully the Great Scott Gadgets team responded quickly to identify and source two available substitute components that (with significant redesign effort) allowed us to begin a production run of HackRF Ones this year. Since identifying substitute components earlier this year, our engineering team has completed a new revision of HackRF One to accommodate the substitutions while continuing to deliver the performance users expect from HackRF One. Production of this new revision is currently in progress.
Thanks to the diligent work of our engineering team, the HackRF One shortage will not be as long as we had initially feared based on the component delays. However, our warehouse shelves are empty at the moment as we wait for our China-based contract manufacturer to complete production. We currently have almost 2,000 units in HackRF One backorders from our resellers waiting to be filled. Last week, we learned that the COVID-19 outbreak in China will delay production into January 2023, and possibly into the Chinese New Year holiday, when the factory will close for a couple of weeks near the end of January. That means that we can expect delivery to resellers in February 2023 if there are no further unforeseen delays.
If you have a preorder in with one of our resellers for HackRF One, please be patient with them. It’s likely that, like Great Scott Gadgets, they planned ahead and did everything they could to keep HackRF One in stock, but there are many things happening right now that are beyond their (and our) control. We thank you for your continued support of our resellers and of Great Scott Gadgets.
Introducing Opera Cake
Starting this week, we are shipping Opera Cake, our multi-use antenna-switching add-on for HackRF One!

This add-on board has two primary ports, each connected to any of eight secondary ports, and it is optimized for use as a pair of 1x4 switches or as a single 1x8 switch.
As a 1x8 switch, Opera Cake can connect your HackRF to a variety of antennas at once, such as a long wire antenna for HF bands, a discone for VHF and UHF, a dipole for 2.4 GHz, and a dish for a satellite band. Once connected to your Opera Cake you can switch between all of your antennas in software instead of making physical hardware swaps.

When set up as a pair of 1x4 switches you could use Opera Cake as a switched filter bank. To do this, connect port A1 to B1, A2 to B2, A3 to B3, and A4 to B4 through physical SMA filters and cables of your choosing. This setup allows you to change your transmit or receive to be through the filter of your choosing without having to reconnect hardware every time you would like to use a different filter.

You can control Opera Cake for HackRF One manually with our command-line software hackrf_operacake, or you can configure HackRF One’s firmware to automatically switch Opera Cake ports based on frequency or time. Automated antenna switching and hackrf_operacake are both available in the latest HackRF One release. You can learn more about Opera Cake’s modes of operation in our HackRF documentation.
If you are looking to pick up an Opera Cake of your own, please check our website for the list of Great Scott Gadgets Opera Cake resellers. We hope you enjoy Opera Cake and stop by our Discord, or tag us on Twitter or Instagram, to show us your Opera Cake projects!
Pseudo-Doppler Redux, ShmooCon 2018
Back in 2018 Michael Ossmann teamed up with Schuyler St. Leger at ShmooCon to present “Pseudo-Doppler Redux”; a talk about taking a modern approach to the implementation of pseudo-doppler direction finding (DF) with Software Defined Radio (SDR). This presentation demonstrates what pseudo-doppler direction finding is and gives an example of Opera Cake usage.
We hope you enjoy watching the presentation!
Testing a HackRF Clone
Like every open source hardware company, we’ve seen clones of our products for sale on the Internet. These clones arguably provide a valuable service to the community, making our designs more widely available and at a price more people can afford. However, they also have negative effects such as an increase on our technical support burden without a corresponding increase in revenue to pay our staff. When the quality of a clone is poor it may also degrade the reputation of our products.
Our most frequently cloned product is HackRF One. While we have every reason to believe that some of the HackRF clones on the market are perfectly functional, we’ve seen users struggle to get others to work at all. Some of the clones have been completely dead on arrival or have had other hardware problems. In general, it seems that few of the clones have been tested by their manufacturers. This can be particularly problematic if returns are not accepted.
We recently decided for the first time to order a HackRF clone and test it to see how well it performs. We chose this particular clone because it has an updated design claimed to improve upon our own design. We’re interested in potential improvements we can make to our own product, and it seemed that the easiest way to test these modifications would be to simply buy the modified clone.
When we plugged the clone in, it appeared to function normally. It had shipped with firmware built from the Havoc repository. This makes some sense as the seller also sells a clone of Jared Boone’s excellent PortaPack. If someone were to purchase both products, the PortaPack would work out-of-the-box with the installed firmware. We weren’t testing with a PortaPack, so we did some initial tests with the installed firmware and then replaced the firmware with a fresh build from our repository.
After confirming basic functionality, we executed a sweep to test the maximum
output power across the entire 6 GHz frequency range. We did this by scripting
a sequence of hackrf_transfer transmit commands while the device was
connected to a spectrum analyzer. The results were troubling.
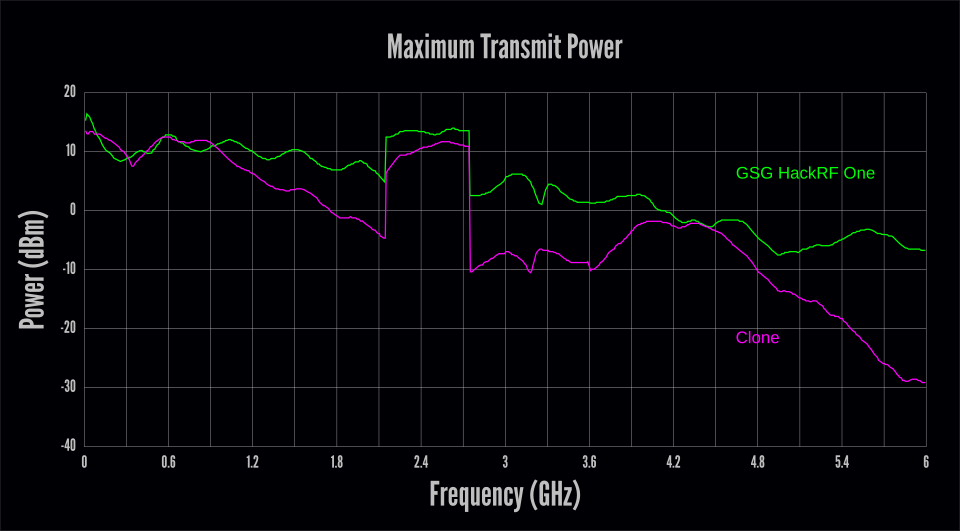
The clone clearly suffered from performance problems above 1 GHz, generally getting worse at higher frequencies. At 6 GHz, this culminated in a whopping 22 dB of loss compared to the GSG HackRF One. (That means that the GSG device produced more than 150 times the output power of the clone.)
It is important to realize that we tested just one sample clone, so our results may not be representative of the average performance of this model. On the other hand, although these results are compared to a single Great Scott Gadgets HackRF One, we know that every GSG HackRF One is factory-tested to ensure that it meets our performance standards.
Next we tested the receive performance by using
QSpectrumAnalyzer with the
hackrf_sweep backend. We set the gain to 40 in QSpectrumAnalyzer which
results in moderate values for the two internal RX gain stages but leaves the
RF amplifier off. We connected the device to a signal generator producing a
-30 dBm signal, slowly swept across the 6 GHz frequency range.
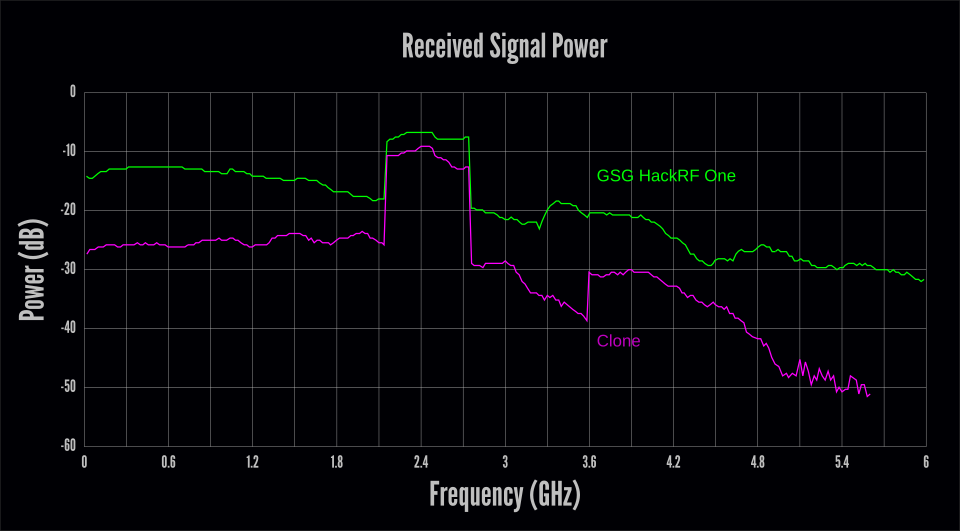
The receive results were even worse than the transmit results. While the transmit test indicated performance problems above 1 GHz, the receive test revealed problems across the entire frequency range. Above 5 GHz the received signal was buried in the noise floor, completely undetectable above 5.6 GHz by QSpectrumAnalyzer with these settings. Note that the RF amplifier was disabled in the receive test but had been enabled in the transmit test.
At this point we ran the clone through our factory test procedure which, in agreement with the previous results, indicated multiple failures at both high and low frequencies. This unit would not have passed our quality control.
We suspected that there may have been multiple reasons for these failures including problems with the design changes as well as manufacturing defects. We didn’t think it would be worth our time trying to isolate every problem, but we did want to explore the effect of the most interesting modification to the design, a protection circuit purported to reduce susceptibility to damage in the RF front end. The simplest way we thought of to test the performance impact of the modification was to remove it and retest the board without the protection circuit in place.
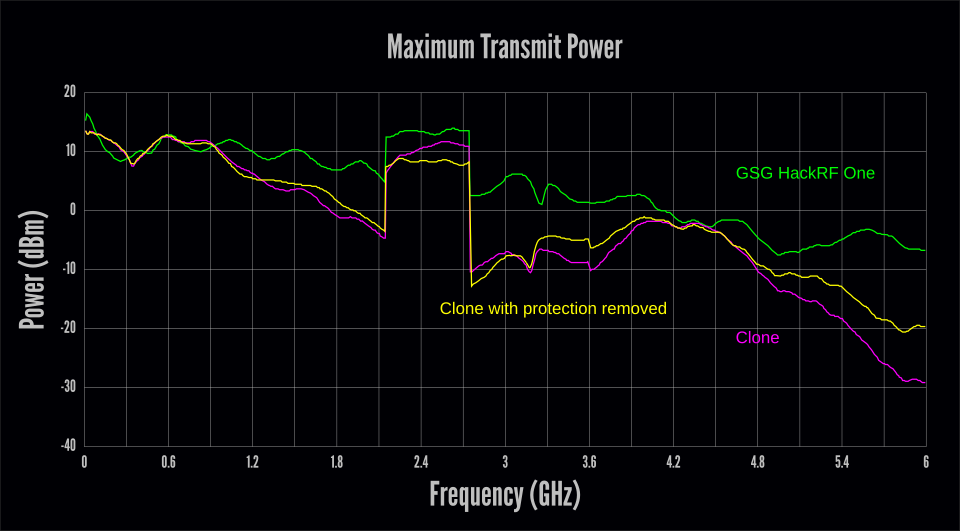
A repeat of the transmit test allowed us to see how the protection circuit affected signal power at various frequencies. As we suspected, a significant portion of the loss at higher frequencies was eliminated by removing the protection circuit. However, the average performance below 5 GHz was little changed, suggesting the presence of additional design or manufacturing flaws.
10 dB of loss at the high end of the frequency range seems to us like a steep price to pay for some protection. HackRF One is already weakest at 6 GHz. If it were that much weaker, I’m not sure we would be comfortable advertising 6 GHz capability.
We are interested in increasing the robustness of the HackRF front end, but any changes we make would need to maintain acceptable RF performance. Perhaps some performance loss in exchange for protection could be acceptable if the protection were proven by test results. We have not seen any test results for the effectiveness of the protection circuit on this HackRF clone, but it is clear from our tests that its effect on RF performance is not acceptable.
HackRF One has an RX input rating of -5dBm. To the best of our knowledge, it is not possible to damage the front end without exceeding this level. We are working on identifying reproducible scenarios that can cause damage to the RF front end so that we can set up reliable and repeatable tests for front end protection. This will enable us to test changes that might increase the RX input rating and reduce the chance of damage in the field.
We’re able to continue supporting and developing HackRF One and other tools thanks to the many people who choose to purchase genuine Great Scott Gadgets products. Every GSG HackRF One is tested for quality at the factory. We provide technical support for our products, and we accept returns of faulty units through our authorized resellers.
Hopefully some of the HackRF clones on the market perform better than the one we tested. The best way we know of to ensure delivery of a working HackRF is to buy it from one of our resellers. If you’ve bought hardware from us for this reason or just because you want to support our ongoing open source development, thank you very much!
Shutting Down GSG Project-Specific Mailing Lists
Thank you to everyone who has been a part of the GSG project mailing lists. We at Great Scott Gadgets appreciate all of the conversations and friendships that have been forged on these lists. Over the last few years we have not given our project-specific mailing lists the attention they deserve; instead we have been focusing our efforts on Discord and GitHub. As such, we will be disabling all the mailing lists except for GSG-announce. Links to the mailing list archives for Ubertooth, YARD Stick One, GreatFET One, and HackRF will all remain available on their individual product pages. Current links to the archives are here:
Talking about GreatFET with Limor "Ladyada" Fried at Adafruit, 2019
In this interview, Michael Ossmann visits Adafruit in New York and chats with Limor “Ladyada” Fried about GreatFET and HackRF. The two talk about what GreatFET neighbours are, how to design GreatFET neighbours, and Mike demonstrates how to use a wiggler to separate neighbours from a GreatFET. This is followed up with a short discussion on HackRF and Portapack and how they work together.
We Fixed the Glitch
Around the first of the year our contract manufacturer contacted us about an urgent problem with HackRF One production. They'd had to stop production because units coming off the line were failing at a high rate. This was quite a surprise because HackRF One is a mature product that has been manufactured regularly for a few years. I continued to find surprises as I went through the process of troubleshooting the problem, and I thought it made a fascinating tale that would be worth sharing.
The reported failure was an inability to write firmware to the flash memory on the board. Our attention quickly turned to the flash chip itself because it was the one thing that had changed since the previous production. The original flash chip in the design had been discontinued, so we had selected a replacement from the same manufacturer. Although we had been careful to test the new chip prior to production, it seemed that somehow the change had resulted in a high failure rate.

Had we overlooked a failure mode because we had tested too small a quantity of the new flash chips? Had the sample parts we tested been different than the parts used in the production? We quickly ordered parts from multiple sources and had our contract manufacturer send us some of their parts and new boards for testing. We began testing parts as soon as they arrived at our lab, but even after days of testing samples from various sources we were unable to reproduce the failures reported by the contract manufacturer.
At one point I thought I managed to reproduce the failure on one of the new boards, but it only happened about 3% of the time. This failure happened regardless of which flash chip was used, and it was easy to work around by retrying. If it happened on the production line it probably wouldn't even be noticed because it was indistinguishable from a simple user error such as a poor cable connection or a missed button press. Eventually I determined that this low probability failure mode was something that affected older boards as well. It is something we might be able to fix, but it is a low priority. It certainly wasn't the same failure mode that had stopped production.
It seemed that the new flash chip caused no problems, but then what could be causing the failures at the factory? We had them ship us more sample boards, specifically requesting boards that had exhibited failures. They had intended to send us those in the first shipment but accidentally left them out of the package. Because the flash chip was so strongly suspected at the time, we'd all thought that we'd be able to reproduce the failure with one or more of the many chips in that package anyway. One thing that had made it difficult for them to know which boards to ship was that any board that passed testing once would never fail again. For this reason they had deemed it more important to send us fresh, untested boards than boards that had failed and later passed.
When the second batch of boards from the contract manufacturer arrived, we immediately started testing them. We weren't able to reproduce the failure on the first board in the shipment. We weren't able to reproduce the failure on the second board either! Fortunately the next three boards exhibited the failure, and we were finally able to observe the problem in our lab. I isolated the failure to something that happened before the actual programming of the flash, so I was able to develop a test procedure that left the flash empty, avoiding the scenario in which a board that passed once would never fail again. Even after being able to reliably reproduce the failure, it took several days of troubleshooting to fully understand the problem. It was a frustrating process at the time, but the root cause turned out to be quite an interesting bug.
Although the initial symptom was a failure to program flash, the means of programming flash on a new board is actually a multi-step process. First the HackRF One is booted in Device Firmware Upgrade (DFU) mode. This is done by holding down the DFU button while powering on or resetting the board. In DFU mode, the HackRF's microcontroller executes a DFU bootloader function stored in ROM. The host computer speaks to the bootloader over USB and loads HackRF firmware into RAM. Then the bootloader executes this firmware which appears as a new USB device to the host. Finally the host uses a function of the firmware running in RAM to load another version of the firmware over USB and onto the flash chip.
I found that the failure happened at the step in which the DFU bootloader launches our firmware from RAM. The load of firmware over USB into RAM appeared to work, but then the DFU bootloader dropped off the bus and the USB host was unable to re-enumerate the device. I probed the board with a voltmeter and oscilloscope, but nearly everything looked as expected. There was a fairly significant voltage glitch on the microcontroller's power supply (VCC), but a probe of a known good board from a previous production revealed a similar glitch. I made a note of it as something to investigate in the future, but it didn't seem to be anything new.
I connected a Black Magic Probe and investigated the state of the microcontroller before and after the failure. Before the failure, the program counter pointed to the ROM region that contains the DFU bootloader. After the failure, the program counter still pointed to the ROM region, suggesting that control may never have passed to the HackRF firmware. I inspected RAM after the failure and found that our firmware was in the correct place but that the first 16 bytes had been replaced by 0xff. It made sense that the bootloader would not attempt to execute our code because it is supposed to perform an integrity check over the first few bytes. Since those bytes were corrupted, the bootloader should have refused to jump to our code.
I monitored the USB communication to see if the firmware image was corrupted before being delivered to the bootloader, but the first 16 bytes were correct in transit. Nothing looked out of the ordinary on USB except that there was no indication that the HackRF firmware had started up. After the bootloader accepted the firmware image, it dropped off the bus, and then the bus was silent.
As my testing progressed, I began to notice a curious thing, and our contract manufacturer reported the very same observation: The RF LED on the board sometimes was dimly illuminated in DFU mode and sometimes was completely off. Whenever it was off, the failure would occur; whenever it was dimly on, the board would pass testing. This inconsistency in the state of the RF LED is something that we had observed for years. I had never given it much thought but assumed it may have been caused by some known bugs in reset functions of the microcontroller. Suddenly this behavior was very interesting because it was strongly correlated with the new failure! What causes the RF LED to sometimes be dimly on at boot time? What causes the new failure? Could they be caused by the same thing?
I took a look at the schematic which reminded me that the RF LED is not connected to a General-Purpose Input/Output (GPIO) pin of the microcontroller. Instead it directly indicates the state of the power supply (VAA) for the RF section of the board. When VAA is low (below about 1.5 Volts), the RF LED is off. When VAA is at or near 3.3 Volts (the same voltage as VCC), the RF LED should be fully on. If the RF LED is dimly on, VAA must be at approximately 2 Volts, the forward voltage of the LED. This isn't enough voltage to power the chips in the RF section, but it is enough to dimly illuminate the LED.

VAA is derived from VCC but is controlled by a MOSFET which switches VAA on and off. At boot time, the MOSFET should be switched off, but somehow some current can leak into VAA. I wasn't sure if this leakage was due to the state of the GPIO signal that controls the MOSFET (!VAA_ENABLE) or if it could be from one of several digital control signals that extend from the VCC power domain into the VAA power domain. I probed all of those signals on both a good board and a failing board but didn't find any significant differences. It wasn't clear why VAA was sometimes partially charged at start-up, and I couldn't find any indication of what might be different between a good board and a bad board.
One thing that was clear was that the RF LED was always dimly illuminated immediately after a failure. If I reset a board into DFU mode using the reset button after a failure, the RF LED would remain dimly lit, and the failure would be avoided on the second attempt. If I reset a board into DFU mode by removing and restoring power instead of using the reset button, the RF LED state became unpredictable. The procedural workaround of retrying with the reset button would have been sufficient to proceed with manufacturing except that we were nervous about shipping boards that would give end users trouble if they need to recover from a load of faulty firmware. It might be a support nightmare to have units in the field that do not provide a reliable means of restoring firmware. We certainly wanted to at least understand the root cause of the problem before agreeing to ship units that would require users to follow a procedural workaround.
Meanwhile I had removed a large number of components from one of the failing boards. I had started this process after determining that the flash chip was not causing the problem. In order to prove this without a doubt, I entirely removed the flash chip from a failing board and was still able to reproduce the failure. I had continued removing components that seemed unrelated to the failure just to prove to myself that they were not involved. When investigating the correlation with VAA, I tried removing the MOSFET (Q3) and found that the failure did not occur when Q3 was absent! I also found that removal of the ferrite filter (FB2) on VAA or the capacitor (C105) would prevent the failure. Whenever any of these three components was removed, the failure could be avoided. I tried cutting the trace (P36) that connects the VAA MOSFET and filter to the rest of VAA. Even without any connection to the load, I could prevent the failure by removing any of those three components and induce the failure by restoring all three. Perhaps the charging of VAA was not only correlated with the failure but was somehow the cause of the failure!
This prompted me to spend some time investigating VAA, VCC, and !VAA_ENABLE more thoroughly. I wanted to fully understand why VAA was sometimes partially charged and why the failure only happened when it was uncharged. I used an oscilloscope to probe all three signals simultaneously, and I tried triggering on changes to any of the three. Before long I found that triggering on !VAA_ENABLE was most fruitful. It turned out that !VAA_ENABLE was being pulled low very briefly at the approximate time of the failure. This signal was meant to remain high until the HackRF firmware pulls it low to switch on VAA. Why was the DFU bootloader toggling this pin before executing our firmware?
Had something changed in the DFU bootloader ROM? I used the Black Magic Probe to dump the ROM from one of the new microcontrollers, but it was the same as the ROM on older ones. I even swapped the microcontrollers of a good board and a bad board; the bad board continued to fail even with a known good microcontroller, and the good board never exhibited a problem with the new microcontroller installed. I investigated the behavior of !VAA_ENABLE on a good board and found that a similar glitch happened prior to the point in time at which the HackRF firmware pulls it low. I didn't understand what was different between a good board and a bad board, but it seemed that this behavior of !VAA_ENABLE was somehow responsible for the failure.
The transient change in !VAA_ENABLE caused a small rise in VAA and a brief, very small dip in VCC. It didn't look like this dip would be enough to cause a problem on the microcontroller, but, on the assumption that it might, I experimented with ways to avoid affecting VCC as much. I found that a reliable hardware workaround was to install a 1 kΩ resistor between VAA and VCC. This caused VAA to always be partially charged prior to !VAA_ENABLE being toggled, and it prevented the failure. It wasn't a very attractive workaround because there isn't a good place to install the resistor without changing the layout of the board, but we were able to confirm that it was effective on all boards that suffered from the failure.
Trying to determine why the DFU bootloader might toggle !VAA_ENABLE, I looked at the documented functions available on the microcontroller's pin that is used for that signal. Its default function is GPIO, but it has a secondary function as a part of an external memory interface. Was it possible that the DFU bootloader was activating the external memory interface when writing the firmware to internal RAM? Had I made a terrible error when I selected that pin years ago, unaware of this bootloader behavior?
Unfortunately the DFU bootloader is a ROM function provided by the microcontroller vendor, so we don't have source code for it. I did some cursory reverse engineering of the ROM but couldn't find any indication that it possesses the capability of activating the external memory interface. I tried using the Black Magic Probe to single step through instructions, but it wasn't fast enough to avoid USB timeouts while single stepping. I set a watchpoint on a register that should be set when powering up the external memory interface, but it never seemed to happen. Then I tried setting a watchpoint on the register that sets the pin function, and suddenly something very surprising was revealed to me. The first time the pin function was set was in my own code executing from RAM. The bootloader was actually executing my firmware even when the failure occurred!
After a brief moment of disbelief I realized what was going on. The reason I had thought that my firmware never ran was that the program counter pointed to ROM both before and after the failure, but that wasn't because my code never executed. A ROM function was running after the failure because the microcontroller was being reset during the failure. The failure was occurring during execution of my own code and was likely something I could fix in software! Part of the reason I had misinterpreted this behavior was that I had been thinking about the bootloader as "the DFU bootloader", but it is actually a unified bootloader that supports several different boot methods. Even when booting to flash memory, the default boot option for HackRF One, the first code executed by the microcontroller is the bootloader in ROM which later passes control to the firmware in flash. You don't hold down the DFU button to cause the bootloader to execute, you hold down the button to instruct the bootloader to load code from USB DFU instead of flash.
Suddenly I understood that the memory corruption was something that happened as an effect of the failure; it wasn't part of the cause. I also understood why the failure did not seem to occur after a board passed testing once. During the test, firmware is written to flash. If the failure occurs at any time thereafter, the microcontroller resets and boots from flash, behaving similarly to how it would behave if it had correctly executed code that had been loaded via USB into RAM. The reason the board was stuck in a ROM function after a failure on a board with empty flash was simply that the bootloader was unable to detect valid firmware in flash after reset.
It seemed clear that the microcontroller must be experiencing a reset due to a voltage glitch on VCC, but the glitch that I had observed on failing boards seemed too small to have caused a reset. When I realized this, I took some more measurements of VCC and zoomed out to a wider view on the oscilloscope. There was a second glitch! The second glitch in VCC was much bigger than the first. It was also caused by !VAA_ENABLE being pulled low, but this time it was held low long enough to have a much larger effect on VCC. In fact, this was the same glitch that I had previously observed on known good boards. I then determined that the first glitch was caused by a minor bug in the way our firmware configured the GPIO pin. The second glitch was caused by the deliberate activation of !VAA_ENABLE.
 glitch caused by rapid charging of VAA (orange) when !VAA_ENABLE (yellow) is pulled low")
When a good board starts up, it pulls !VAA_ENABLE low to activate the MOSFET that switches on VAA. At this time, quite a bit of current gets dumped into the capacitor (C105) in a short amount of time. This is a perfect recipe for causing a brief drop in VCC. I knew about this potential problem when I designed the circuit, but I guess I didn't carefully measure it at the time. It never seemed to cause a problem on my prototypes.
When a bad board starts up, the exact same thing happens except the voltage drop of VCC is just a little bit deeper. This causes a microcontroller reset, resulting in !VAA_ENABLE being pulled high again. During this brief glitch VAA becomes partially charged, which is why the RF LED is dimly lit after a failure. If VAA is partially charged before !VAA_ENABLE is pulled low, less current is required to fully charge it, so the voltage glitch on VCC isn't deep enough to cause a reset.
At this point I figured out that the reason the state of the RF LED is unpredictable after power is applied is that it depends on how long power has been removed from the board. If you unplug a board with VAA at least partially charged but then plug it back in within two seconds, VAA will still be partially charged. If you leave it disconnected from power for at least five seconds, VAA will be thoroughly discharged and the RF LED will be off after plugging it back in.
This sort of voltage glitch is something hardware hackers introduce at times as a fault injection attack to cause microcontrollers to misbehave in useful ways. In this case, my microcontroller was glitching itself, which was not a good thing! Fortunately I was able to fix the problem by rapidly toggling !VAA_ENABLE many times, causing VAA to charge more slowly and avoiding the VCC glitch.
 glitch avoided by rapid toggling of !VAA_ENABLE (yellow) to slowly charge of VAA (orange)")
I'm still not entirely sure why boards from the new production seem to be more sensitive to this failure than older boards, but I have a guess. My guess is that a certain percentage of units have always suffered from this problem but that they have gone undetected. The people programming the boards in previous productions may have figured out on their own that they could save time by using the reset button instead of unplugging a board and plugging it back in to try again. If they did so, they would have had a very high success rate on second attempts even when programming failed the first time. If a new employee or two were doing the programming this time, they may have followed their instructions more carefully, removing failing boards from power before re-testing them.
Even if my guess is wrong, it seems that my design was always very close to having this problem. Known good boards suffered from less of a glitch, but they still experienced a glitch that was close to the threshold that would cause a reset. It is entirely possible that subtle changes in the characteristics of capacitors or other components on the board could cause this glitch to be greater or smaller from one batch to the next.
Once a HackRF One has had its flash programmed, the problem is very likely to go undetected forever. It turns out that this glitch can happen even when a board is booted from flash, not just when starting it up in DFU mode. When starting from flash, however, a glitch-induced reset results in another boot from flash, this time with VAA charged up a little bit more. After one or two resets that happen in the blink of an eye, it starts up normally without a glitch. Unless you know what to look for, it is quite unlikely that you would ever detect the fault.
Because of this and the fact that we didn't have a way to distinguish between firmware running from flash and RAM, the failure was difficult for us to reproduce and observe reliably before we understood it. Another thing that complicated troubleshooting was that I was very focused on looking for something that had changed since the previous production. It turned out that the voltage glitch was only subtly worse than it was on the older boards I tested, so I overlooked it as a possible cause. I don't know that it was necessarily wrong to have this focus, but I might have found the root cause faster had I concentrated more on understanding the problem and less on trying to find things that had changed.
In the end I found that it was my own hardware design that caused the problem. It was another example of something Jared Boone often says. I call it ShareBrained's Razor: "If your project is broken, it is probably your fault.". It isn't your compiler or your components or your tools; it is something you did yourself.
Thank you to everyone who helped with this troubleshooting process, especially the entire GSG team, Etonnet, and Kate Temkin. Also thank you to the pioneers of antibiotics without which I would have had a significantly more difficult recovery from the bronchitis that afflicted me during this effort!
ANT700 Release
Today we are excited to announce the official release of ANT700, our new 300—1100 MHz telescopic antenna. Because this general purpose antenna was designed with YARD Stick One users in mind, it has a slim and lightweight form factor that works well with smaller devices. It has an SMA male connector to attach to your device of choice (including HackRF One) and can be extended from 9.5 cm to 24.5 cm.
We started distributing ANT700 last month, and it is already available for purchase from six of our authorized resellers on four continents. To find out where you can purchase yours, please visit the product page.

Rapid Radio Reversing, ToorCon 2015
In this video of Michael Ossmann’s presentation at ToorCon 2015, he demonstrates how helpful it can be to use a combination of both SDR and non-SDR tools for reverse engineering wireless systems. Michael uses both HackRF One and YARD Stick One to reverse engineer a wireless cabinet lock.
You can download and watch the video on Internet Archive here.
The code from the presentation is in Michael Ossmann’s stealthlock repository.
PortaPack H1 at DEF CON 23
Jared Boone of ShareBrained Technology gave demonstrations of his new PortaPack H1 at the DEF CON 23 Demo Lab. I joined him at his table to help talk with people about the add-on for HackRF One.

PortaPack H1 turns HackRF One into a portable SDR platform. With an LCD, navigation control, and audio input and output, the device can be used as a handheld spectrum analyzer and can implement a wide variety of useful radio functions. A microSD slot on the PortaPack can be used for waveform or firmware storage, and a coin cell keeps the real-time clock and a small amount of configuration RAM going while the device is turned off.

Of course, the hardware designs and firmware for PortaPack H1 are published under an open source license. Jared has done an amazing job of implementing SDR functions for PortaPack that run entirely on HackRF One's ARM Cortex-M4 microcontroller.
To use PortaPack H1, you'll need a HackRF One, and you'll probably want a USB battery pack to make it a fully portable solution. Another popular add-on is the beautiful milled Aluminum enclosure for PortaPack. Jared provides a ShareBrained Technology guitar pick with every PortaPack H1. It is the perfect tool for opening your HackRF One's injection molded plastic enclosure prior to PortaPack installation.
There was a wonderful moment at the Demo Lab when Jared tuned his PortaPack to a frequency being used by Ang Cui at a nearby table. Jared's PortaPack was plugged in to a small speaker, so we could all listen to the AM radio transmission originating from a printer at Ang's table. The printer was physically unmodified but was running malicious software that transmitted radio signals with a funtenna! For more information about Ang's implementation, visit funtenna.org.
My First Look at rad1o Badge
Over the next several days, thousands of hackers will gather at the Chaos Communication Camp in Germany. An electronic badge for the event is being prepared, and it is based on my design for HackRF One!
At DEF CON over the weekend, I was fortunate to be able to meet up with Ray, one of the members of the Munich CCC group responsible for the rad1o badge. Ray was wearing one of the prototype units, so I was able to take a close look.

The design is a variation of HackRF One. It includes a small LCD and an audio interface, so it is a bit like having a HackRF One plus a PortaPack H1 on a single board. A slim, rechargeable LiPo battery is mounted on the back. The visual design of the PCB looks like a traditional AM/FM radio receiver complete with an antenna (which is not the actual RF antenna) and a dial (which is not really a dial).
There are some design modifications, especially in the RF section, that seemed strange to me at first. The reason for many of these changes is that the rad1o team was able to get certain chip vendors to agree to sponsor the badge by donating parts. By redesigning around donated components they were able to reduce the cost to a small fraction of the cost of manufacturing HackRF One, making it possible to build the rad1o badge for several thousand campers.
The firmware for rad1o is derived from HackRF One firmware but is in a separate repository. Because of the LCD and other differences between the two hardware designs, they are not firmware-compatible. When using rad1o as a USB peripheral, it is fully supported by existing software that supports HackRF One. Future rad1o firmware will use a USB product ID of 0xCC15 assigned from the Openmoko pool, but the shipping firmware will borrow HackRF One's product ID. This will ensure that any existing software for HackRF One will work with rad1o during camp. The new product ID (0xCC15) is already supported in libhackrf release 2015.07.2, so it should be easy for people to update to it in the near future.
If you are new to Software Defined Radio and are looking forward to using the badge as a way to get started with SDR, I recommend starting with my video series. You might want to download the videos before leaving for camp. Also take a look at Getting Started with HackRF and GNU Radio and the recommended software for rad1o. If you plan to do firmware or hardware hacking, be sure to clone the rad1o repositories. For examples of Digital Signal Processing (DSP) on the LPC43xx, I suggest studying Jared Boone's firmware for PortaPack H1. Also check out the video of Jared's Software-Defined Radio Signal Processing with a $5 Microcontroller at BSidesLV 2015.
As an open source hardware developer, it is extremely satisfying to see folks start with my design and do something amazing like the rad1o badge. I'm excited to be attending camp for my first time ever, and I can't wait to see the projects people will come up with!
HackRF One at 1 MHz
We've decided to advertise the fact that HackRF One operates all the way down to 1 MHz, not just to 10 MHz. This isn't a change to the hardware design; it is simply an acknowledgment that the hardware has always worked at such low frequencies and that we support operation down to 1 MHz.
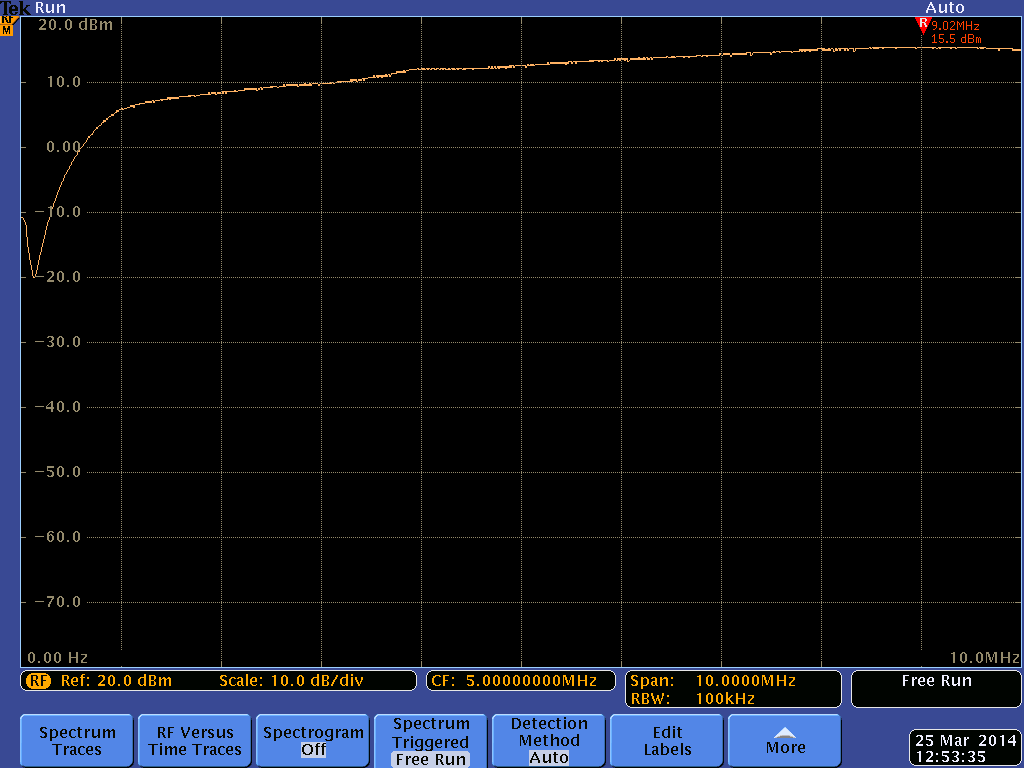
In fact, HackRF One can even function below 1 MHz, but the performance drops considerably as the frequency decreases. The curve is reasonably flat down to about 1 MHz, so we consider that to be the lower limit for most uses.
Now that we've seen consistent low frequency performance across multiple manufacturing runs, we're comfortable changing the official specification: HackRF One operates from 1 MHz to 6 GHz. Try attaching a long wire antenna to listen to shortwave radio!
Although HackRF One has reasonable performance down to 1 MHz, it performs better at higher frequencies. To get the best possible performance down to 1 MHz and lower, I recommend using an external upconverter/downconverter such as the excellent Ham It Up, open source hardware designed by Opendous.