
Great Scott Gadgets
Speeding up CRC calculations for Bluetooth Low Energy
Over the past few days Mike Ryan has been working hard to cram as much of the Bluetooth Low Energy (BTLE) functionality as possible in to the Ubertooth firmware. In doing so he plans to relieve the host system of the work involved in finding and processing packets. In time this will allow Ubertooth to monitor and inject packets in to BTLE connections while running from a very low powered host, or possibly without a host system at all.
This has involved some excellent work using the CC2400 chip to automatically detect BTLE packets, a task which it is unfortunately unable to achieve for basic rate Bluetooth. Once we know where a packet starts we are able to handle the packet data as a set of bytes rather than needing to break the data up in to bits before running through the whitening and CRC algorithms.
While Mike worked on the whitening algorithm, he set the CRC as an open challenge, which I gladly took up. I thought that it may make an interesting post to explain how CRC algorithms are implemented and show how to trade off time for memory, or time for space complexity for the computational theorists among us, by using a look up table (LUT). This may be common knowledge to many people and there are automated tools to achieve it, but I wanted to work it out by hand.
This part is, at least in part, for my own reference when I look at the code in a year’s time and ask “who did that? And how o we know it’s correct?”
Linear Feedback Shift Registers
Linear Feedback Sift Registers (LFSRs) are often used for CRC checks, forward error correction or to generate pseudo-random data. They are computationally cheap and simple to implement in hardware if required, so they are perfect for low cost networking chips. Bluetooth uses them to implement data whitening, header error checks, CRCs and forward error correction on packet data.
The LFSR that implements the CRC on BTLE packets looks something like this:
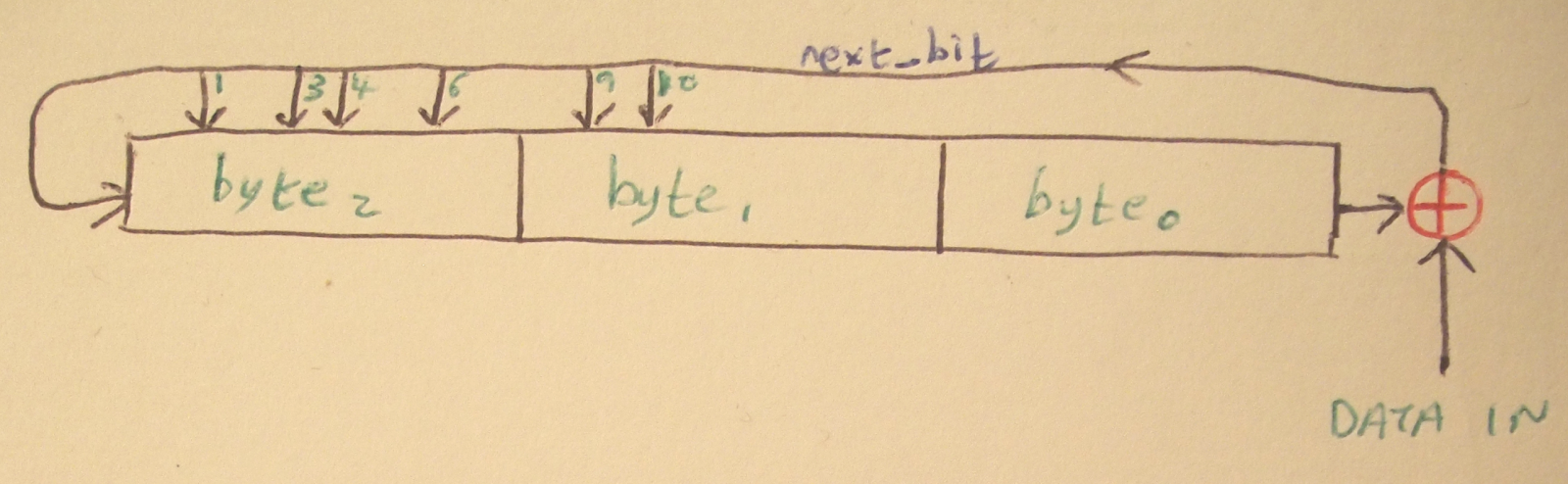
The LFSR for CRC on BTLE packets as drawn by me. See Vol 6, part B, Section 3.2 of the Bluetooth specification for a better, but non-free version of the diagram. For simplicity we can imagine the LFSR as parts, a shift register and the feedback element, using XOR. Each incoming bit of packet data is XOR’d with the right-most bit of the register, for consistency we’ll assume that the bits are numbered 0-23 from left to right. Bit 23 is XOR’d with the incoming data bit and becomes next_bit. The register is shifted one bit to the right and next_bit is added to the end, becoming bit 0. This is a shift register.
Now for the feedback part, each of those arrows feeding in to the top of the register represents a bit in the register that will be XOR’d with next_bit. T\hat is all you need to know about LFSRs for most usese, in fact it should be trivial to implement one using the above information. Here’s our implementation of the above LFSR:
u32 btle_calc_crc(u32 crc_init, u8 *data, int len) {
u32 state = crc_init;
u32 lfsr_mask = 0x5a6000; // 010110100110000000000000
int i, j;
for (i = 0; i < len; ++i) {
u8 cur = data[i];
for (j = 0; j < 8; ++j) {
int next_bit = (state ^ cur) & 1;
cur >>= 1;
state >>= 1;
if (next_bit) {
state |= 1 << 23;
state ^= lfsr_mask;
}
}
}
return state;
}
Optimising the LFSR
As you can see, we run through the inner loop for each bit of data, although we only perform the XOR if we next_bit was set. This is a very small optimisation that makes use of the shift operation filling with 0s and the fact that XOR with 0 would have no effect. Logically this process looks a little like this:

The LFSR split in to a shift and a feedback, or XOR, component. The diagram above shows the two stage LFSR, with the second stage containing the different masks to be XOR’d with the register depending on the state of next_bit. This is a two value look up table holding 24 bits od XOR mask.
If we can shift then look up the XOR for one bit, why not more? As long as we shift by the appropriate amount, the XOR result only relies on the incoming data and the state of the register. Even better, there is no feedback in to the lowest byte of the register, so early bits in an incoming byte don’t affect the value of later bits.
Working with Bytes
Taking a byte of input data, we first XOR it with the lowest byte of the register to get next_byte, then we shift the register to the right by a byte and append next_byte. This takes care of the shift.
To finish off we need to apply the eight XOR masks based on the content of next_byte. As the register is shifted for each bit, the masks are XOR’d together with each successive mask shifted by one bit, this is shown in the diagram below.

The final mask is produced by XORing the mask for each bit of next_byte.
The derived mask is specific to the next_byte value of 01101101, so we are able to store it in a table and retrieve it for future use. If we do this for all 256 values of next_byte we can build a full look up table, and use it to calculate the CRC.
The following code implements the CRC using a LUT:
u32 crcgen_lut(u32 crc_init, char *payload, int len)
{
u32 state = crc_init;
int i;
u8 key;
for (i = 0; i < len; ++i) {
key = payload[i] ^ (state & 0xff);
state = (state >> 8) ^ crc_lut[key];
}
return state;
}
The LUT itself consists of 256 32bit values, so is too large to reproduce here, but it can be found on Github.
While it is possible to write code to that builds the LUT from shifted masks for each value of next_byte, it was easier to use the known good implementation of the CRC algorithm given earlier to provide the final state of the register for all one byte payloads and then XOR it with the pre-mask state, as shown below.
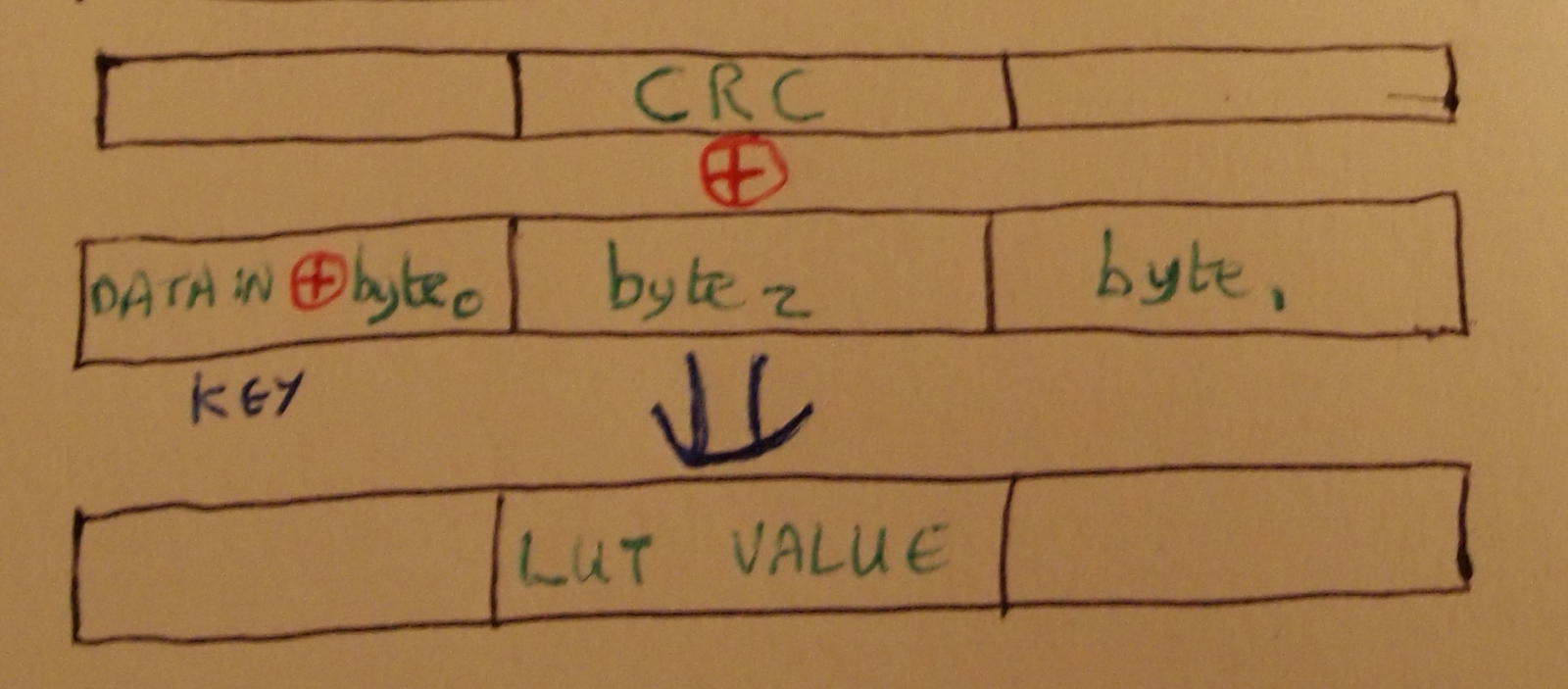
The XOR mask for each key is calculated and then stored in the LUT. After looking at the code, Michael Ossmann pointed out that leaving the key byte blank while building the LUT would yield the same result and avoid a pointless shift operation in the final algorithm. It seems that no matter how nerdy you try to be, someone will out-geek you.